
TL;DR
- Volt on AWS’s Graviton ARM platform is roughly 40% faster than a comparable Intel CPU.
- Operating costs on Volt on AWS’s Graviton ARM platform can be as low as 64% of Intel’s, based on spot instance pricing in the AWS Dublin region.
- The raw performance improvement is due to c7g not using hardware threading, while Intel uses two hardware threads per physical core, which increases latency once you get beyond 50% CPU usage.
- Over time, Volt can achieve over 4,000 TPS out of an ARM pair and about 3,500 out of an Intel pair for the tested workload.
- Volt offers a TCO benefit of around 33% when running on Graviton, but real-world long-term pricing could be up to 50% cheaper, depending on your AWS agreement.
Mission-critical applications require great performance without breaking the bank.
In this light, we are always seeking to prove Volt’s value against other data platforms for supporting applications that need to be fast without compromising on things like accuracy, consistency, or resiliency.
As part of our new support for ARM processors, we recently ran benchmarks on both Intel C7 and ARM c7g on AWS. The goal of these benchmarks was to both quantify performance differences between the two platforms and gain an understanding of their TCO.
We used an in-house benchmark called voltdb-charglt. This simulated a telco charging workload and was intentionally elaborate for the sake of being as realistic as possible, with each call leading to anything up to a dozen SQL statements being executed. It also allows you to run a KV store.
The results showed that based on the current pricing, Volt on AWS’s Graviton ARM platform is roughly 40% faster than a comparable Intel CPU and has operating costs that can be as low as 64% of Intel’s, based on spot instance pricing in the AWS Dublin region.
Obviously, these numbers are not cast in stone because AWS can change them at any time for any reason, and large AWS customers often have their own pricing agreements.
The raw performance improvement is due to c7g not using hardware threading, while Intel uses two hardware threads per physical core, which increases latency once you get beyond 50% CPU usage.
Benchmark Setup
To emulate real-world scaling behavior, we started with a small, 3-node cluster and increased the workload until the 99th percentile latency exceeded 10ms. We then moved up to a more powerful 3-node cluster. Eventually making the 3-node cluster more powerful stopped leading to a matching increase in performance as we saturated the local IO. Rather than trying to use ‘better’ IO, which would have significantly increased costs, we expanded to a 5-node cluster of the previous hardware, then 7, and finally 9.
In practice, by the time we reached the limits of a 7-node cluster, we were saturating the local network. While this could be addressed, it was outside the scope of this benchmark. So, while we know that Volt will support workloads in at least the high single-digit millions, we didn’t do it here.
File systems and IO
Regardless of size, each server always has the same IO configuration. We have arrived at this through extensive empirical research as well as trial and error. It represents a trade-off between TCO and capability.
| Device | Purpose | Configuration |
| / | Root | gp2, 128 Gib, 100 IOPS, no throughput defined |
| /voltdbdatassd1 | Command Logs | gp2, 128 GiB, 384 IOPS, no throughput defined |
| /voltdbdatassd2 | Snapshots + Topics | gp3 128 GiB 3000 IOPS, 500 Throughout |
Tested hardware configurations and their TCO
We calculated TCO on the following assumptions:
- AWS spot pricing for the Dublin region
- File systems as defined above with no extra or special networking
- No ingress or egress fees
The tested configurations and hourly operating costs were:

Charging Demo Performance
The graph below was created by running our benchmark repeatedly, stepping up the required throughput until it could no longer be done with a 99th percentile latency of <= 10ms. We then shifted to a bigger server.
Note that because we always have one spare copy of data, we were actually measuring the thousands of TPS per pair of cores. Over time, this settles down and we can squeeze over 4,000 TPS out of an ARM pair and about 3,500 out of an Intel pair for our workload.
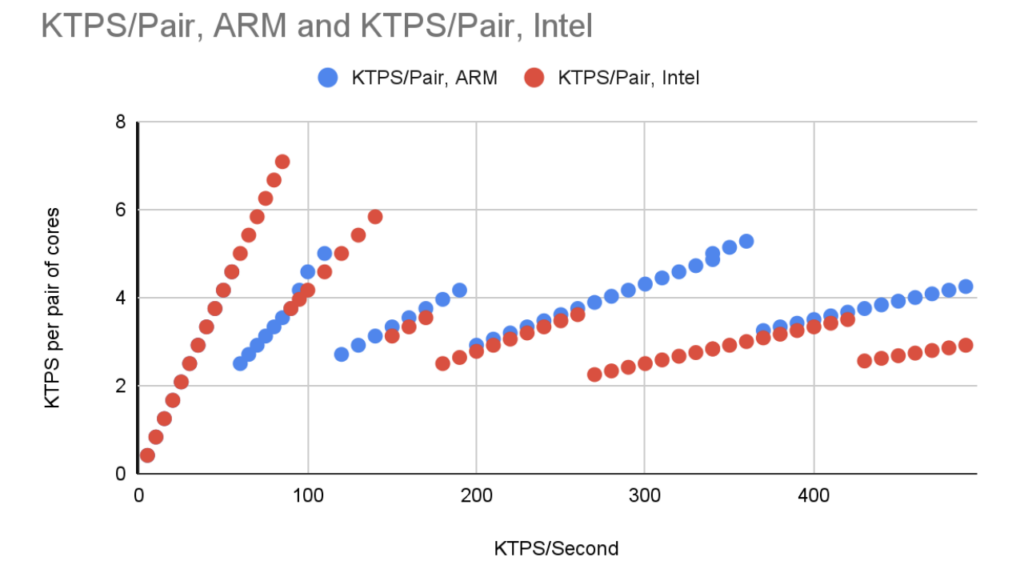
Because there are only a finite number of possible server configurations, it’s not practical to ‘perfectly’ size a server for a given workload. As a consequence, when you first move to a new, bigger cluster your TCO is high and you only gain maximum benefit just as you reach the limits of a given configuration. The graph below shows this nicely.
What is “KTPS/Pair”? In order to achieve high availability in Volt, each transaction is performed at least twice, simultaneously. on two different physical servers. So when we look at sizing we think in terms of pairs of cores, assuming one spare copy of each data item.
Note that the graph shows the cost of providing the capability to run 100K TPS for one hour.
Initially the numbers look terrible, but that’s because we’re running a tiny workload on a moderately powerful cluster. As the workload increases the cost stabilizes, and then remains remarkably stable as the workload grows. However, if we go much beyond 500K TPS, we need to use a non-default networking structure.
While there is nothing physically stopping us scaling to a TPS in the millions, our goal was to do a benchmark that you, the reader, could reproduce without rocket science skills or spending huge amounts of money.
The average cost of ARM was consistently lower.
Also note that the graph above shows that as the TPS goes past 200K, a clear difference appears between ARM and Intel.
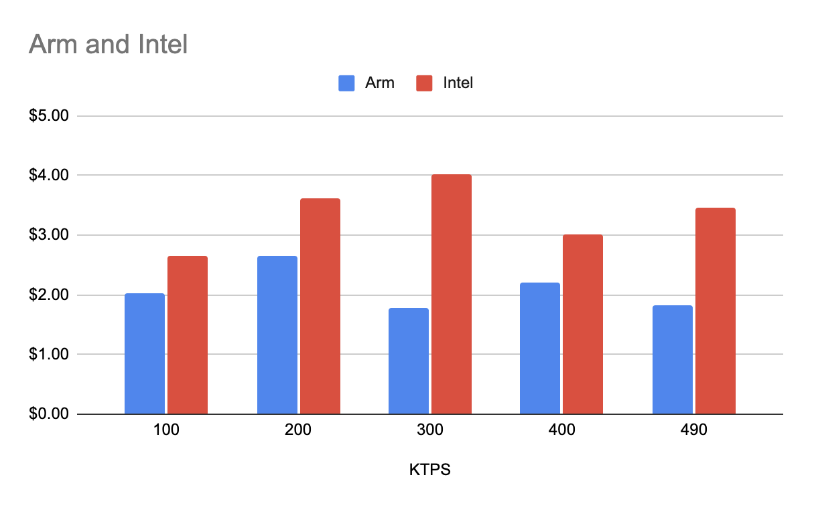
Conclusion
We know Volt runs well on Graviton, and in the examples above we see a clear benefit of around 33% from a TCO perspective.
However, we used AWS spot pricing. Real-world long-term pricing could be up to 50% cheaper. Whether you could get the same discount from AWS for both Intel and ARM is something you’re going to have to ask your AWS rep about.
You should not be paying more than around US$4/hour for each 100,000 TPS that you need to
support, assuming your application has the same level of complexity as our reference one. Note that Volt can do in one trip what most NoSQL data platforms require multiple trips to do.
So, you may find yourself in a situation where what would be a 1:1 relationship between logical transactions and physical transactions in Volt turns into five or more physical calls to the cluster for each logical transaction, which you’ll need to factor into your calculations.
In short: If you need large numbers of ACID transactions, at scale, in a millisecond time scale, and also want to have manageable TCO, you need Volt.
Learn more about why Volt is the only no-compromise data platform built for mission-critical applications at scale.






