We’ve added a new feature in Volt Active Data v6.6: support for joins in materialized views. We’re very pleased to share this update with you. Read on for use cases and practical suggestions.
Fast data applications rely heavily on DBMSs like Volt Active Data to provide steady support for many continuous and complex queries returning aggregate and summary data. Such queries are usually referenced in applications repeatedly, but they can be very expensive to run. To serve these queries with better performance, Volt Active Data supports materialized views which can cache the aggregate query results in special read-only tables. Once a view is created, Volt Active Data will keep the view content in sync with any updates to the view source tables, incrementally, with minimal cost.
The advantages of using a materialized view include the ability to:
- Shorten the query execution time by directly accessing the cached result.
- Hide a query’s complexity by replacing complex query structures with a simple view table reference.
In earlier versions of Volt Active Data, materialized views supported aggregate queries involving COUNT(), SUM(), MIN(), and MAX() on one single table. However, new application use cases showed that aggregating data spread over multiple tables is also very widely used by customers for various reasons:
- Database designers usually need to enforce data normalization by fitting the data into several tables when designing database schemas. When using the database to support transactions, it is sometimes necessary to join the tables back together to get a more readable aggregate result;
- Specific in-DBMS analytical computations require joins as an indispensable step. Examples are matrix multiplications, recursive queries, and some geographical computations.
Beginning in version 6.6, materialized views in Volt Active Data support aggregate queries involving more than one base table. Joining tables together requires a lot more effort than scanning one single table, so it can be a performance killer. Volt Active Data’s ability to have multi-table continuous aggregate queries covered by materialized views can be beneficial to the performance of fast data applications. Therefore, this is a big step forward for enhancing our support for continuous queries.
To show how a materialized view on a join query works, let’s begin with a simple example showing summarized statistics of taxi trajectory data, aggregated by geographical regions.
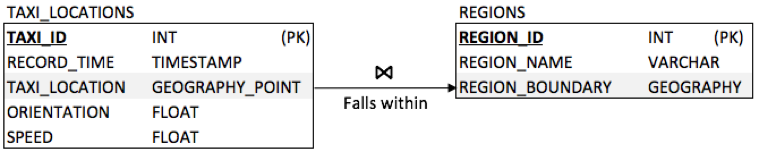
Figure 1 The database design to store taxi trajectory data and geographical region definitions
Figure 1 shows a simplified database design to store taxi trajectory data and related geographical region definitions. In this design, we leveraged Volt Active Data’s recently introduced geographical data types “GEOGRAPHY_POINT” and “GEOGRAPHY” to keep the location information and the region boundaries as polygons.
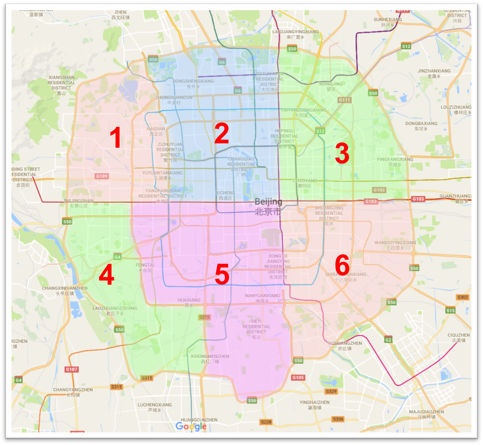
Figure 2 Hypothetical regions in Beijing
Figure 2 shows a map of Beijing with six simple hypothetical regions. Each region is represented as a polygon using a series of coordinates for the vertices of the polygon. The trajectory data used to build this example is collected from sensors installed in around 28,000 taxis in Beijing, which are approximately 42% of the total (about 67,000). The sensors report the location of a taxi every few minutes. This data is very useful to provide insights into Beijing’s traffic conditions. Analysis can be done by continuously querying some aggregated results as sensor data is being sent back to the datacenter to discover interesting trends or abnormalities. Below is a simple example query:
SELECT REGIONS.REGION_ID,
COUNT(*) FROM REGIONS JOIN TAXI_LOCATIONS ON
CONTAINS(REGIONS.REGION_BOUNDARY, TAXI_LOCATIONS.TAXI_LOCATION)
GROUP BY REGIONS.REGION_ID;
This query groups all taxi location data by regions and returns a count of data records for each region. The result can very roughly illustrate the ‘busyness’ of the delimited regions. In this case, a join between the TAXI_LOCATIONS table and the REGIONS table is required to match each location record with the region it fell into, using the geography function “CONTAINS” which Volt Active Data provides as part of its geospatial features.
Volt Active Data generates a nested loop plan for the execution engine to evaluate the join in this query, which is very slow even with the help of indices. A test run on a typical 2015 MacBook Pro environment took almost 10 seconds to process around 10 million records. That basically means whenever you want to identify the current busiest regions using this query, it can only give you the busiest region “10 seconds ago”.
To reduce this delay, we can create a materialized view to cache the result of this query:
CREATE VIEW V (REGION_ID, RECORD_COUNT) AS
SELECT REGIONS.REGION_ID,
COUNT(*) FROM REGIONS JOIN TAXI_LOCATIONS ON
CONTAINS(REGIONS.REGION_BOUNDARY, TAXI_LOCATIONS.TAXI_LOCATION)
GROUP BY REGIONS.REGION_ID;
From this point on, table V will always contain the up-to-date result of its defining query, adding a negligible single digit millisecond maintenance overhead for every update operation on the base tables. But the performance gain, on the other hand, is significant. The time to return the result of this aggregate query drops to a few milliseconds from 10 seconds. Notice that as more data is inserted into the base table, the time to execute this query from scratch will keep growing, while the view maintenance overhead will not increase as much. This is because Volt Active Data maintains materialized views continuously in an incremental manner, that is, when the source tables are updated, instead of recomputing the view from scratch. Volt Active Data will only compute the minimal set of changes to be made to the affected materialized views. In the case of views on join queries, a tiny join operation will be executed to get the affected tuples in the view on every update operation. Just as with any queries involving joins, creating indices on the join keys stands out as a very good optimization because it can help Volt Active Data complete the query faster.
We are continuing our work on materialized views on join queries to further optimize the feature to be more efficient and useful. Give it a try and let us know what you think!

