When you evaluate a database to use in your application stack, you usually look at the features, the performance, the price, and the fit. You take for granted that the data is correct, that the features work as documented, and that the resiliency of your distributed database meets the promises made by the marketing team. Our customers depend on Volt Active Data in a variety of solutions, for example serving ads, analyzing streaming meter data, and provisioning mobile calls. They depend on our database in critical parts of their businesses – often the parts that connect to their customers’ business value. At Volt Active Data, we believe that protecting your data and theirs is as important as any feature we build. To show you how we stand by our commitments to our customers, we thought we’d share how we test our product.
Must Read: 5g Telco Based Solutions
Good processes and a culture of quality
We have developed a set of processes that bake quality in from beginning to end.
Agile development – planning with a strong “Definition of Done”
We are an Agile shop. Quality starts before any code is written. We have several feature teams, each with four to seven developers and one Software Engineer in Test. The teams work in two-week iterations. Quality and testing is part of each task and is the responsibility of all team members, not just the test engineer. We groom user stories carefully — determining relative sizing, technical requirements and, of course, how they will be tested, including any acceptance tests. The stories always include writing automated tests, and the tests are reviewed as part of all code reviews, and are run by our trusty continuous integration server, Jenkins. It’s quite common for review comments to ask for more tests. In addition to user stories, we also create regression tests for all defect fixes that are run against all future check-ins.
During coding – Continuous Integration
We have a Jenkins server that manages our continuous integration. It runs our tests on a farm of 60+ servers in-house and can elastically use more servers in Amazon’s cloud (EC2). During the day most servers are running the unit tests for all the topic branches, as well as our master branch. At night our servers shift to the system test responsibility – allowing us to run longer tests and to test on clusters of various topologies. We have machines running all supported operating systems (currently two versions of Centos/RedHat, three versions of Ubuntu, and OSX) plus a variety of bare-metal servers and virtualization technologies, including kvm and Docker, with more on the way (VMware), as well as a few varieties of Java (7, 8, OpenJDK, Oracle).
After we ship – Engineering has direct responsibility for customer experience
The Customer Support and Success organization reports to the VP of Engineering. There is no organizational “us” vs. “them” when it comes to critical customer issues. In fact, the link is even tighter – I manage both QA and Support. The tests we run directly reflect experiences in the field. If a feature is having problems at a customer site or is being used in a way we didn’t imagine, the feedback into the engineering team, and also into our tests, is rapid.
Tests – and lots of them
We take several approaches to testing. This section covers the types of testing that happen before we ship product. Follow-on posts will drill down into some of these topics.
“Unit Tests” on all topic branches
“Unit test” is the usual name for tests that run on all code checkins, but at Volt Active Data it deserves the quotes emphasis. We have more than our share of unit tests, but we also have built up a large body of tests using jUnit that are really cluster-in-a-box, black-box, and grey-box tests. In total, we run 3600+ testcases and regression tests, including some that spin up full clusters on a box. These tests would take several hours if run sequentially, but we split them up to run in several Docker containers at once and get our results in under 30 minutes (for more information, see John Hugg’s presentation on how we use Docker to speed up testing). In addition, we have C++ unit tests that run on all supported operating systems, a valgrind smoketest, SQL tests and a distribution test.
Figure 1: Jenkins folders for each topic branch. Each contains 10 jobs that must pass before being allowed to merge to master
Figure 2: The 10 jobs within a topic folder. As you can see, this one is not quite ready to merge.
Randomized SQL tests against another SQL reference database
All new SQL features get jUnit tests, but we also use a home-grown randomized SQL Generator, sqlcoverage that runs SQL in Volt Active Data and compares it against the same SQL run against HSQLDB. The tool randomizes the SQL using templates, allowing for many more combinations of features than jUnit tests can possibly cover.
Extended “Unit” Tests on master and release branches
A few times a day, we schedule some extended tests, running the same tests with valgrind (a memory leak checker), debug assertions, a managed-ByteBuffer memory leak checker (Volt Active Data does a some buffering off-heap), and a few other tools. In addition, we run an extended randomized SQL test and a few static analyzers, such as findbugs and a copy-paste detector.
System Integration Tests of all our features and failures
We continuously run multi-machine tests that run combinations of all of our features, supported platforms, and failure modes. The matrix of tests is ever-expanding, with dimensions such as:
- Topologies: cluster size, replication-factor, number of partitions per host
- Features: command logging, auto-snapshotting, inter-cluster replication, streaming export, streaming import, tunable settings, …
- Integrations: export and import to JDBC, Kafka, HDFS …
- Environments: supported OS, varied virtualization, supported JDK …
- Failure modes (and their repair actions): killed nodes, killed processes, failed network links, network partitions, killed clusters …
- Client settings: transaction mix, transaction rates, data sizes, data types …
Against this backdrop of settings and environments, we run workloads and test scripts that check data consistency, correctness, and availability, and then scrape logs for unexpected errors. Our most frequently used workload, txnid-selfcheck2, contains stored procedures and client application code specially designed to detect flaws in Volt Active Data’s transaction system – which guarantees serializable Isolation. For more information on this workload, be sure to check out John Hugg’s Strangeloop 2015 talk, “All In With Determinism for Performance and Testing in Distributed Systems”.
By randomizing the settings and actions in each test, we’ve found and fixed the kinds of intermittent issues from race conditions, weird configurations and subtle feature incompatibilities that are very hard to figure out in the field. In my dual role as manager of QA and support, I’m keenly aware that more time spent on this in QA means less time spent in support! These tests run around the clock and range from short – 20 minutes – to six hours, just running and injecting faults.
We also run a series of longevity tests. We run for a week at a time and have two jobs running: one that just runs our voltkv example, and another that runs with occasional faults injected. These longer tests enable us to detect slow memory leaks, performance slowdowns and other issues that are only visible over long time periods.
Performance
We wouldn’t claim the mantle of fast data without running a lot of performance tests. We run 175+ performance benchmarks every night, producing over 500 historical performance measurement charts. These range from full applications, such as voter, and tpc-c to benchmarks of discrete functions, such as the impact of materialized views and command-logging. We review the output weekly and don’t release if Volt Active Data slows down.
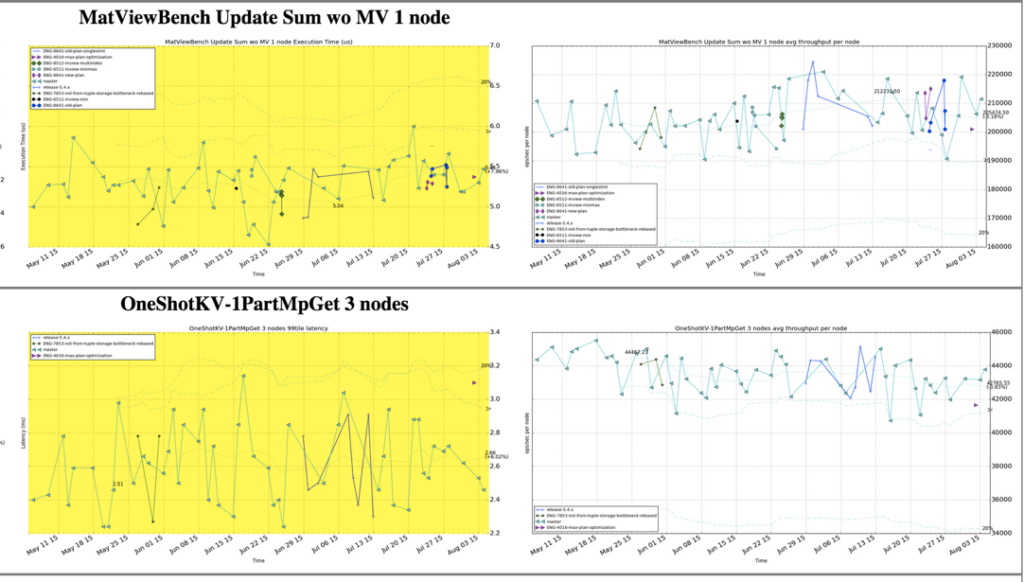
Figure 3: Charts from our performance page showing latency and throughput graphs from two benchmarks.
Interfaces and API Tests
Some Volt Active Data tests make sure the product is usable, and also that the features, interfaces and APIs work as intended. These range from automation of some of the bin/ scripts (more are being automated all the time), to client library tests, Selenium-based tests of the Volt Active Data Management Center, and a manual checklist we execute before releases.
Conclusion
Building distributed systems is hard, and so is testing them. We handle this by building quality into the entire engineering culture, into our processes, and by writing and running a lot of tests. We would always rather debug problems here in our test lab than ship them off to you. We sleep better when you don’t have to call us to report a system problem late at night!

